BlazingSQL Execution Graph¶
SQL Query to relational algebra¶
When a user runs a query using bc.sql(query), that query is sent to Apache Calcite where it is parsed into relational algebra and then optimized. That optimized algebra comes back into python and can always be viewed by calling bc.explain(query). The optimized relational algebra is sent via dask to each of its workers along with sources of information (cudfs, or files).
On each worker the relational algebra is converted into a physical plan. Every relational algebra step maps to 1 or more physical plan steps. That physical plan is then used to construct an execution graph which is a DAG of Kernels and Caches.
Execution Graph: DAG of Kernels and Caches¶
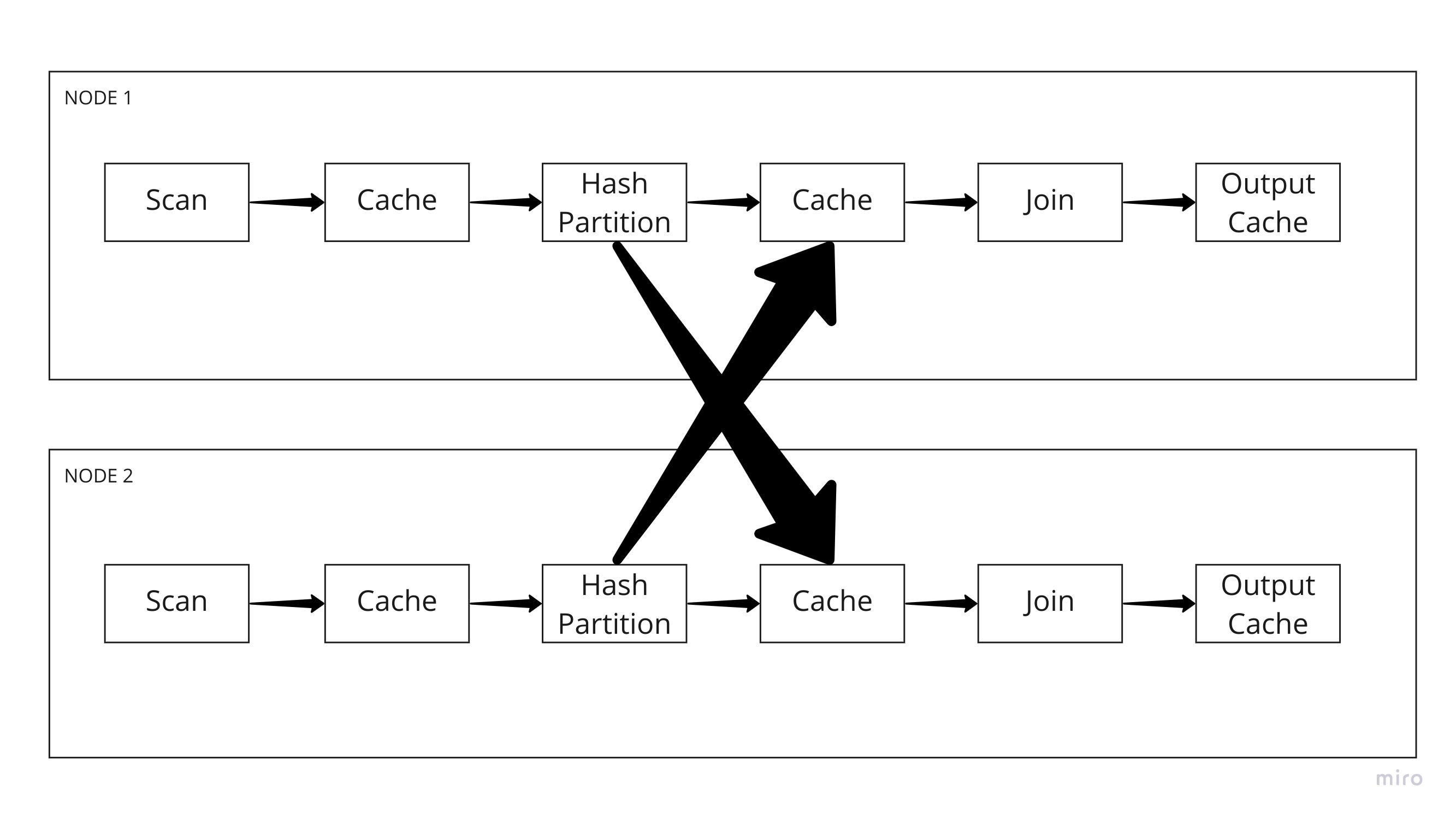
The execution graph is a directed acyclic graph with nodes that are kernels and caches that are edges. The above image gives a good overview of how we try to organize various operations that need to be performed on one or more dataframes or groups of files. Every kernel is connected to every other kernel only through a cache. The purpose of the cache is to hold data as a CacheData between computational stages. CacheData objects can move data between different memory layers, so that the data processing algorithms performed can scale to beyond what one single memory layer can hold. All Kernels implement the Kernel interface or one of their derived classes. A kernels purpose is to organize the flow and orchestration of performing complex distributed operations but it does not perform any of the execution itself. Instead, it generates tasks which are sent to the Task Executor, which is the one which will perform the execution itself. The final output of a DAG of kernels and caches is a Cache which will contain the result.
The Kernels push information forward into caches and kernels pull those cached data representations to get inputs. They are decached only right before computation is about to take place.
The engine operates on partitions of data that form part of one larger distributed DataFrame.
That data can reside in GPU, CPU, in local file systems or on distributed file systems like hdfs.
The data can currently only be operated on using a GPU
The DAG is homogenous across the nodes
Data only moves from one kernel to another through a Cache.
Kernels¶
Know what transformations are taking place.
Is not responsible for invoking the execution though it has a function do_process which every kernel must implement.
Keeps track of a tasks completion or failure state.
Can change the implementation of the algorithm they are providing depending on characteristics of the data, topology and resources
Could easily be expanded upon to create kernels that target multiple backends
The kernel being ignorant of what is coming through it allows it to be more concerned with the logical execution of a plan without being tied to one specific execution model. Given that we currently only support the CUDA execution model we have yet to fully seperate these concerns.
A list of the kernels can be found by looking at the derived types found in Kernels and Distributing Kernels
Task Executor and Tasks¶
The task executor’s job is to take all of the jobs in the queue and actually schedule them to run on the hardware that we are targetting. Currently we only target Nvidia GPUs with our executor. It manages access to resources like system and gpu memory and limits the number of tasks that are being executed concurrently. It also is what provides the ability to retry operations that failed due to lack of resources that can be retried when resources are more plentiful.